搜索到
2
篇与
的结果
-
 「已过时不再推荐 请看 LoRA 训练视频」保姆式教程!Embedding 训练教程 让你的AI学会其他画师的画风与人物 {bilibili bvid="BV1C14y157nQ" page=""/}!!!注意:本训练目前已经不再推荐了,不过仍然是一种可用的训练方式!!! 1.pt文件就是训练出来的模型,可以随便拷贝分享。放在embedding文件夹里就可以用了,要填写的tag和你的文件名称一模一样,pt文件名称可以随便改!!2.看教程之前先更新webui、安deepdanbooru。我专栏都教过,可以去翻翻。如果你只训练画风,可以不用deepdanbooru!2023年1月23日更新 :目前训练人物模型无脑选择LoRA:https://www.bilibili.com/video/BV1fs4y1x7p2/训练画风模型推荐训练大模型:https://www.bilibili.com/video/BV1SR4y1y7Lv/具体细节训练方法的选择可以查看:https://www.bilibili.com/read/cv21362202专栏里还有更多AI训练相关知识~
「已过时不再推荐 请看 LoRA 训练视频」保姆式教程!Embedding 训练教程 让你的AI学会其他画师的画风与人物 {bilibili bvid="BV1C14y157nQ" page=""/}!!!注意:本训练目前已经不再推荐了,不过仍然是一种可用的训练方式!!! 1.pt文件就是训练出来的模型,可以随便拷贝分享。放在embedding文件夹里就可以用了,要填写的tag和你的文件名称一模一样,pt文件名称可以随便改!!2.看教程之前先更新webui、安deepdanbooru。我专栏都教过,可以去翻翻。如果你只训练画风,可以不用deepdanbooru!2023年1月23日更新 :目前训练人物模型无脑选择LoRA:https://www.bilibili.com/video/BV1fs4y1x7p2/训练画风模型推荐训练大模型:https://www.bilibili.com/video/BV1SR4y1y7Lv/具体细节训练方法的选择可以查看:https://www.bilibili.com/read/cv21362202专栏里还有更多AI训练相关知识~ -
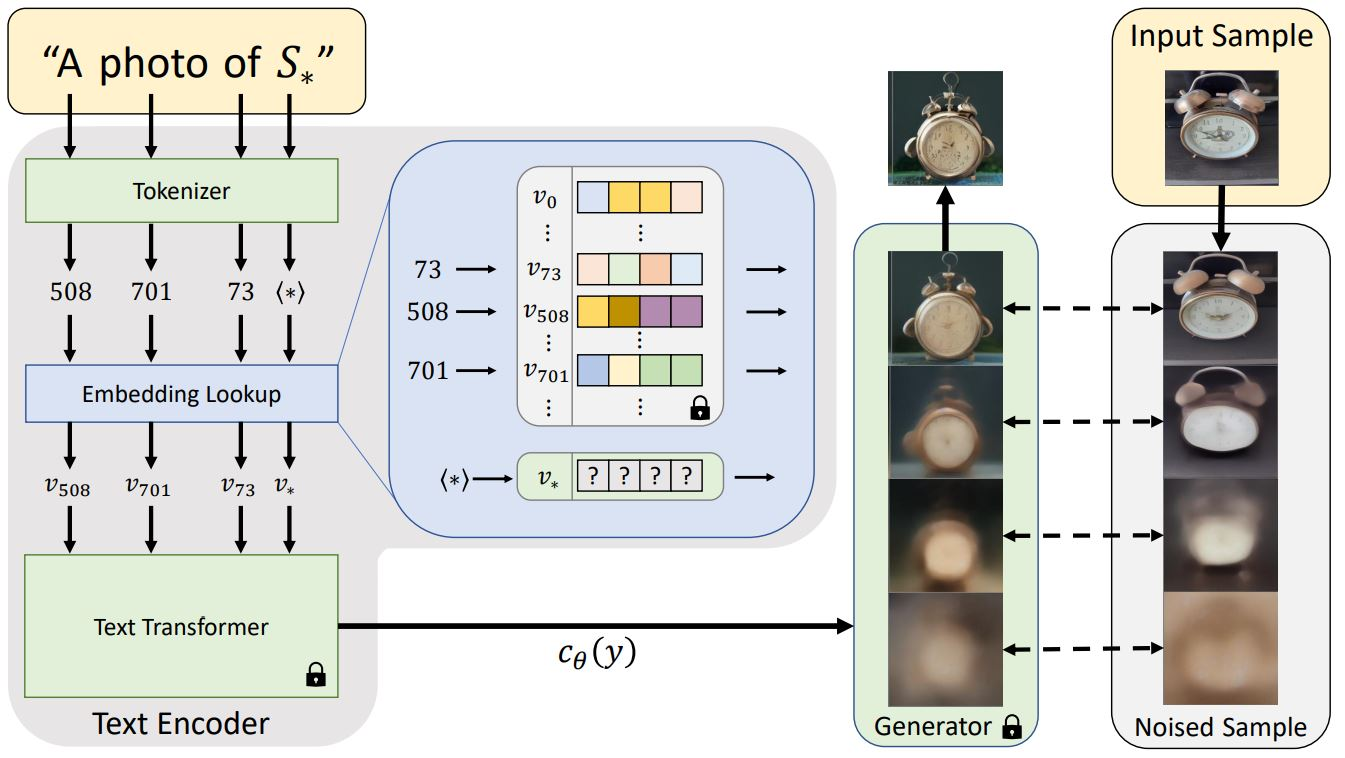
【AI绘画训练教程】当我们在训练AI的时候,究竟在训练什么?AI训练前置知识(一) 原作者 @秋葉aaaki ,本文仅作存档使用收录于文集 AI绘画训练教程 本篇文章写于2022年10月,一些新的训练方法并没有在本篇专栏~ 包括 Dreambooth、LoRA 这两种比较新的训练方法,以后会写新的专栏继续介绍~看了这么多教程,从来没有人讲过这些东西,自己写一个。可能很多人已经下载到别人分享的、各种地方来源的一些“模型”了,但是他们种类繁多——有pt文件,有图片格式的文件:甚至大小差别都很大,有的几十kb,有的要80、90mb左右。那他们究竟都是什么,有什么区别?首先我们要知道,目前来说一般用户可以训练的有两种小模型:一个叫 embedding (Textual Inversion),另外一个叫 hypernetwork 。分辨方法就看大小,小的就是embedding,大的就是hypernetwork 当然,还有一个最主要的巨大无比的模型(novelai泄露的那种、我们常说的4g、7g模型)这个是一般人甚至是实验室的计算资源无法训练的,我们暂且不提。一. Textual Inversion首先从Textual Inversion开始介绍。这个是目前所有训练教程都在教的一个东西,也是最好训练的,最常见的一种这个方法训练出来的模型是embedding,大小约几十到几百kb, 文件类型可以是.pt,.png,.webp等等 。使用这个模型的方法就是放在embedding文件夹里,然后在生成图片的时候就可以输入对应的tag来使用了。这个Textual Inversion究竟是怎么工作的呢?来一起看下面这张图。(看不懂也不要紧) 我们在生成一张图片的时候,要提供prompt(也就是tag)。然后这些词会通过一系列的复杂操作,变成 连续向量 的形式来指导AI去生成对应的图片。embedding训练的过程,就是像在写一本词典。在这本“词典”中,添加一个词的解释 ——用他来翻译AI所不认识的词。来告诉AI:这个词、就是指的这个人物、东西、或者一个风格!训练的过程就是从一堆给定的图片中寻找一个向量,来表示你给的词语。然后再当读取到这个词语的时候,AI就知道了:哦 原来这个词对应的是这个东西这个过程并不会触及到大模型的网络的任何参数以及权重,完完全全是作用在从输入的词到翻译成连续向量的过程上。这也是为什么这个训练出来的模型会如此之小、一张家用显卡在一个小时左右就可以轻松训练出来1w步数左右的模型。这就是“文本反演”(Textual Inversion)——在文本编码器的嵌入空间(embedding)中找到新的伪词,使它可以捕获高级语义和精细视觉细节。[1]二. hypernetwork超网络是一种在不接触任何权重的情况下微调模型的概念。 简单说就是用一个网络来生成另外一个网络的参数 [2]工作原理是:用一个hypernetwork输入训练集数据,然后输出对应模型的参数,最好的输出是这些参数能够使得在测试数据集上取得好的效果。也就是说,他会对整个模型进行微调、无论是什么tag全部起作用。具体的东西过于技术了,有兴趣的朋友可以看引用的这篇论文,我就不再过多介绍了(其实是我太菜不敢教别人)三. 对比与区别说了这么多,那么如何选择训练哪种?我自己的评价是,如果只是想学个人物、简单的画风、一律推荐用Textual Inversion。他能做到只影响部分、甚至是多种不同人物、画风混合等等操作。而且他训练简单方便、快捷。hypernetwork训练经常就过拟合,寄了,不是很好训练。四. 引用[1] Gal R, Alaluf Y, Atzmon Y, et al. An image is worth one word: Personalizing text-to-image generation using textual inversion[J]. arXiv preprint arXiv:2208.01618, 2022.[2] Ha D, Dai A, Le Q V. Hypernetworks[J]. arXiv preprint arXiv:1609.09106, 2016.Source:https://www.bilibili.com/opus/719800097657847848